Présentation de Stable Cascade
Présentation de Stable Cascade

Communiqué de Stability AI
Points clés à retenir:
Aujourd’hui, nous publions Stable Cascade en avant-première de recherche, un nouveau modèle de texte en image s’appuyant sur l’architecture Würstchen. Ce modèle est publié sous une licence non commerciale qui autorise uniquement une utilisation du même type.
Stable Cascade est exceptionnellement facile à former et à affiner sur le matériel grand public grâce à son approche en trois étapes.
En plus de fournir des points de contrôle et des scripts d’inférence, nous publions des scripts pour le réglage fin, la formation ControlNet et LoRA pour permettre aux utilisateurs d’expérimenter davantage cette nouvelle architecture qui peut être trouvée sur la page Stabilité GitHub.
Aujourd’hui, nous lançons Stable Cascade en aperçu de recherche. Ce modèle innovant de conversion texte-image introduit une approche intéressante en trois étapes, établissant de nouvelles références en matière de qualité, de flexibilité, de réglage fin et d’efficacité, en mettant l’accent sur l’élimination des barrières matérielles. De plus, nous publions un code de formation et d’inférence qui peut être trouvé sur le Page GitHub de stabilité pour permettre une personnalisation plus poussée du modèle et de ses sorties. Le modèle est disponible pour inférence dans le bibliothèque de diffuseurs.
Détails techniques
Stable Cascade diffère de notre gamme de modèles Stable Diffusion car elle est construite sur un pipeline comprenant trois modèles distincts : étapes A, B et C. Cette architecture permet une compression hiérarchique des images, obtenant des résultats remarquables tout en utilisant un espace latent hautement compressé. . Examinons chaque étape pour comprendre comment elles s’articulent :

La phase Latent Generator, étape C, transforme les entrées de l’utilisateur en latents compacts 24×24 qui sont transmis à la phase Latent Decoder (étapes A et B), qui est utilisée pour compresser les images, de la même manière que le travail du VAE dans Stable. Diffusion, mais avec une compression beaucoup plus élevée.
En dissociant la génération conditionnelle de texte (étape C) du décodage vers l’espace de pixels haute résolution (étapes A et B), nous pouvons permettre une formation ou des ajustements supplémentaires, y compris les ControlNets et LoRA, à effectuer individuellement à l’étape C. Cela vient avec une réduction des coûts de 16 fois par rapport à la formation d’un modèle de diffusion stable de taille similaire (comme indiqué dans le modèle original papier). Les étapes A et B peuvent éventuellement être affinées pour un contrôle supplémentaire, mais cela serait comparable au réglage fin de la VAE dans un modèle de diffusion stable. Pour la plupart des utilisations, cela apportera un avantage supplémentaire minime et nous suggérons simplement d’entraîner l’étape C et d’utiliser les étapes A et B dans leur état d’origine.
Les étapes C et B seront publiées avec deux modèles différents : les paramètres 1B et 3,6B pour l’étape C et les paramètres 700M et 1,5B pour l’étape B. Il est recommandé d’utiliser le modèle 3.6B pour l’étape C car ce modèle offre des sorties de la plus haute qualité. . Cependant, la version de paramètre 1B peut être utilisée pour ceux qui souhaitent se concentrer sur les exigences matérielles les plus faibles. Pour l’étape B, les deux obtiennent d’excellents résultats, mais le 1,5 milliard excelle dans la reconstruction des détails les plus fins. Grâce à l’approche modulaire de Stable Cascade, les exigences de VRAM attendues pour l’inférence peuvent être maintenues à environ 20 Go, mais peuvent être encore réduites en utilisant des variantes plus petites (comme mentionné précédemment, cela peut également diminuer la qualité de sortie finale).
Comparaison
Au cours de nos évaluations, nous avons constaté que Stable Cascade fonctionnait mieux en termes d’alignement rapide et de qualité esthétique dans presque toutes les comparaisons de modèles. Les figures montrent les résultats d’une évaluation humaine utilisant un mélange de invites partielles et des invites esthétiques :
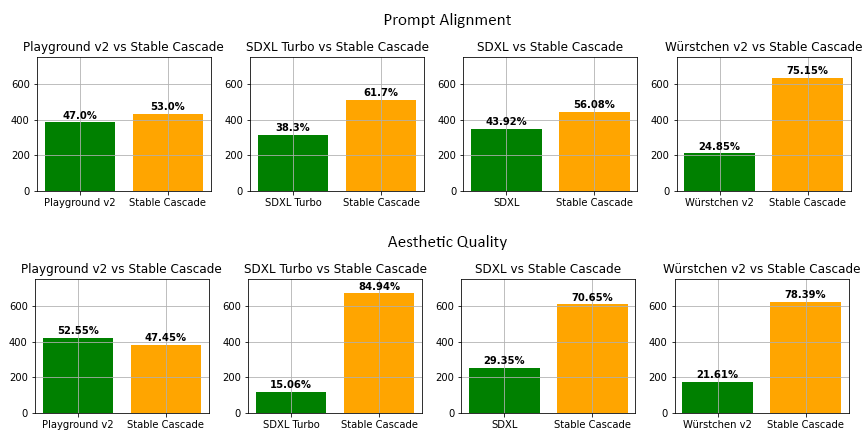
L’image ci-dessus compare Stable Cascade (30 étapes d’inférence) à Playground v2 (50 étapes d’inférence), SDXL (50 étapes d’inférence), SDXL Turbo (1 étape d’inférence) et Würstchen v2 (30 étapes d’inférence).

L’image ci-dessus montre les différences de vitesse d’inférence entre
Cascade stable, SDXL, Playground v2 et SDXL Turbo
L’accent mis par Stable Cascade sur l’efficacité est mis en évidence par son architecture et son espace latent plus compressé. Bien que le plus grand modèle contienne 1,4 milliard de paramètres de plus que Stable Diffusion XL, il présente toujours des temps d’inférence plus rapides, comme le montre la figure ci-dessous.
Caractéristiques supplémentaires
En plus de la génération texte-image standard, Stable Cascade peut générer des variations d’image et des générations image-image.
Les variations d’image fonctionnent en extrayant les intégrations d’images d’une image donnée à l’aide de CLIP, puis en les renvoyant au modèle. Ci-dessous, vous pouvez voir quelques exemples de sorties. L’image de gauche montre l’original, tandis que les quatre à droite sont les variations générées.

L’image à image fonctionne en ajoutant simplement du bruit à une image donnée, puis en l’utilisant comme point de départ pour la génération. Voici un exemple pour bruiter l’image de gauche, puis exécuter la génération à partir de là.

Code pour la formation, le réglage fin, ControlNet et LoRA
Avec la sortie de Stable Cascade, nous publions tout le code pour la formation, le réglage fin, ControlNet et LoRA afin de réduire les exigences pour expérimenter davantage cette architecture. Voici quelques-uns des ControlNets que nous publierons avec le modèle :
Inpainting / Outpainting : saisissez une image associée à un masque pour accompagner une invite de texte. Le modèle remplira ensuite la partie masquée de l’image en suivant l’invite textuelle fournie.

Canny Edge : générez une nouvelle image en suivant les bords d’une image existante entrée dans le modèle. D’après nos tests, il peut également s’étendre sur des croquis.

Dans l’image ci-dessus, les esquisses du haut sont entrées dans le modèle pour produire les sorties du bas.
Super résolution 2x : augmentez l’échelle d’une image en 2x son côté (par exemple, en transformant une image 1024 x 1024 en une sortie 2048 x 2048) et peut également être utilisée sur les latents générées par Stage C.

Les détails de ceux-ci peuvent être trouvés sur le Page GitHub de stabilitéy compris le code de formation et d’inférence.
Bien que ce modèle ne soit actuellement pas disponible à des fins commerciales, si vous souhaitez explorer l’utilisation de l’un de nos autres modèles d’image à des fins commerciales, veuillez visiter notre page d’adhésion à Stability AI pour une utilisation commerciale auto-hébergée ou notre plateforme de développement pour accéder à notre API.






