Advertisement
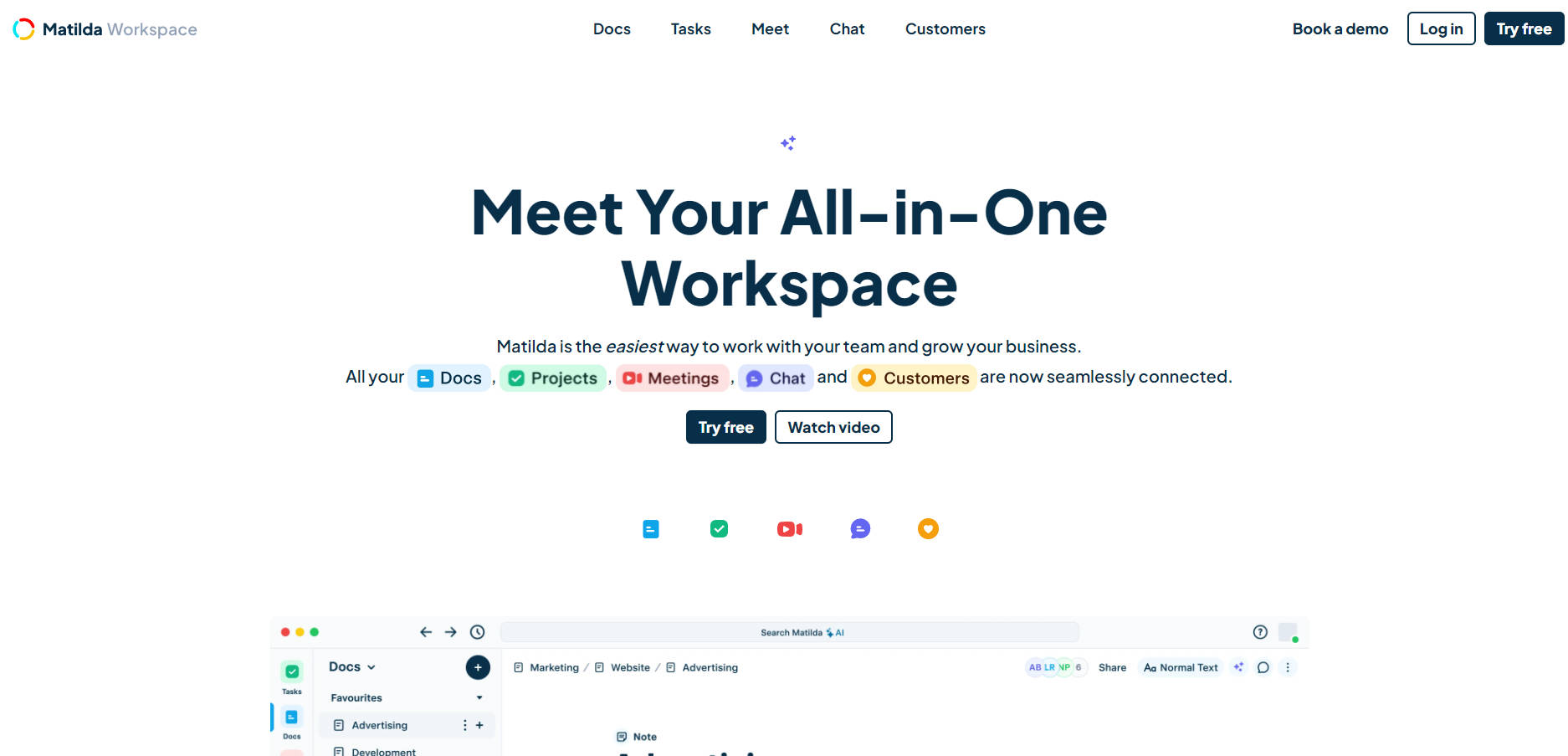
Synthesys AI Audio
Synthesys AI Audio
AI speech synthesizers are software tools that use neural networks and deep learning techniques to imitate human speech. These tools are trained on large datasets of human voice recordings to learn phonemes, intonations, and speech patterns. With the ability to change pitch, tone, and tempo, AI voice synthesizers like Synthesys can produce natural-sounding synthetic voices. They are used for voiceovers, speech synthesis, etc.
Main Features:
1. Word processing: The software takes written text as input, which can be in the form of paragraphs, sentences or longer articles.
2. Text analysis: The AI speech generator analyzes text to understand its linguistic structure, including word order, punctuation and grammatical conventions. It also identifies sentence boundaries and parts of speech.
3. Speech synthesis: By combining phonetic components, prosody and linguistic context, AI generates speech using deep learning models. This includes transformer-based architectures, convolutional neural networks (CNN), and recurrent neural networks (RNN).
Use case:
AI speech synthesizers have a wide range of applications, including:
– Voiceover for videos, advertisements and presentations.
– Text-to-speech for accessibility tools, online learning platforms and virtual assistants.
– Content creation software to generate audio content quickly and efficiently.
Conclusion:
AI speech synthesizers have made significant progress in recent years, resulting in highly realistic synthetic speech. With the ability to personalize voice elements and seamless integration into various applications, these tools have become valuable in areas such as education, entertainment, accessibility, and customer service. Advances in AI text-to-speech technology have made it more accessible and adaptable than ever, improving user experience in several areas.
Vote :




Alternatives to this tool
Text-to-chain in 5 minutes with OpenAI and Toolbox. Toolblox is a no-code smart contract and DApp generator. Source: https://twitter.com/tool_blox/status/1603344382811414528
Speakatoo is an AI-powered text-to-speech tool that allows users to generate high-quality male and female voices in mp3 and wav formats. With Speakatoo, you can[...]
DeepWord is an AI tool that allows users to create and customize videos of people speaking without the need for actors or equipment. By selecting[...]
Unleash the power of AI-driven speech conversion with AnyToSpeech, an easy-to-use text-to-speech tool that effortlessly transforms text, documents, images, and URLs into realistic spoken content.[...]
Studio Max is a virtual studio that lets you easily create professional voiceovers. It offers 26 voices in 11 different Indian languages, making it accessible[...]
Beepbooply is an AI-powered text-to-speech tool that features over 900 voices from Google, Microsoft, and Amazon. With realistic and natural speech patterns, this software allows[...]
Personalized Elf Messages is a tool that allows users to create personalized audio messages from a Christmas elf. It allows users to personalize their message[...]